
A Weird Alien Intelligence
A software engineer on what AI actually can and can't do for his job

David Padawer is a software engineer with about a decade of experience, currently doing iOS development after five years on the backend. He’s worked at everything from 10-person companies to FAANG and is about as far from a Luddite as you can get. He keeps up with AI developments, tests new models regularly, and has had access to GitHub Copilot — with multiple model options — through his job for over a year.
And yet, until recently, he’d found AI to be a surprisingly modest addition to his actual workflow. That’s what made me want to sit down with him. You hear a lot from the hype camp and from the dismissers, but David occupies a more interesting position: a thoughtful practitioner who was genuinely trying to make these tools work and had specific, honest reasons for why they weren’t.
That’s changed recently. This conversation is something of a time capsule — his account of what the roadblocks were, what recently changed, and how he predicts his field will be transformed, from computer science education to the engineering pipeline. This is a lightly edited transcript.
Testing the Models
Ben: Where do you want to start? Until recently, I know you’ve had some test prompts you’ve used with AI to see if it’s ready to help you with coding and you’ve been waiting for the models to clear a certain bar.
David: Yeah — that’s basically my history with AI. Until about a year ago, I’d only been testing the free versions. It’s now common knowledge that there’s a huge disparity between free and paid, but that wasn’t really on my radar until six months ago or so. Through my job I’ve had access to GitHub Copilot, which lets you swap in Gemini, GPT, or Claude under the hood.
My go-to test was: here’s my actual codebase — tell me what buckets of tech debt we have and prioritize them. Give me a numbered list of what order we should address these. Tech debt means issues that aren’t broken but could be cleaned up. It’s kind of like a loan with interest you’re taking against your future self: if it hits a critical mass, it really does start to slow down development.
For a long time, none of the models could categorize tech debt well at all. About six months ago Gemini started getting decent at it. But then I’d say: “Great, I have a numbered list. Why is two lower than one? Why is one the most important?” And without fail, both Gemini and Claude would say: “Oh my god, you’re so right, I’ll switch them.” And I’d think — no. I don’t want you to switch them. I want you to back up what you just said.
My basic definition of a good engineer is someone who has an opinion, has convictions, and has good evidence to back them up. AI just did not pass that muster. To be honest, chat mode still can’t really do this, and I’ve given up on that question.
The Agent Mode Unlock
Ben: But as of the last month or so you’ve started to find these models very useful. What changed?
David: My big unlock came about a month ago when I finally decided to just try agent mode. I was fully expecting it to fail the same way chat mode had. But the first thing it did actually impressed me.
We have this concept of feature flags — a true/false toggle we write into new features. We don’t want users to see the feature yet, so we set it to “off” in the cloud. When we’re ready, we flip it on for everyone — and once it’s on, you can rip out all the code that was checking the flag status, because we never turn things back off.
What the agent was smart enough to do — without any hint from me — was: when deleting an “if flag on / else flag off” block, it knew to preserve the “on” behavior and throw out the “off” behavior entirely. If I’d given that task to an intern, I’d honestly expect a follow-up question: “Quick check — do we want the replacement behavior to be the on state or the off state?” The fact that it didn’t need to ask and just nailed it was impressive.
Then just this week: we have a corner of our codebase where the classes don’t share a parent class or protocol that I can change in one place. For reasons that would take a while to explain, we’re not planning to fix that architecture anytime soon. So I was staring down a one-line change across fifty-something files. I was like, “I just need to sit down and do this for an hour and a half. It’s gonna suck. And I’m a human, so I’ll probably mess up a couple of them.”
Instead I fired up my agent. I asked it to add a new field — “component type,” of type “component type” — and pointed it at some other files showing how to associate a class to its type. One shot. When I reviewed the changes via git diff, I could see it had occasionally overwritten a line instead of inserting one. But scrolling back through the session, it had caught itself on probably 75% of those errors mid-run — it just missed a subset. And it deleted a testing structure it thought was unused; my guess is our tests weren’t in its context window, so it saw “not referenced anywhere” and nuked it. Fixable.
Net result: it saved me an hour, probably two. Five minutes of active time on my end.
Ben: Do you think if you’d jumped straight to agent mode earlier, maybe six months ago, you would have found this value sooner? Or do you think it genuinely wasn’t good enough before?
David: Probably earlier, yeah. Again, for chat mode, I’d tried having it write code for me to copy-paste, or explain what to change in a file, and it was never great at that. So I extrapolated: therefore agent mode also won’t work. A coworker finally just told me to just try it and he was right. I probably could have been using it much earlier.
A Weird Alien Intelligence
Ben: I want to zoom in on the heuristic you were going for with your test prompt — a good engineer has an opinion and defends it to pushback. That’s cutting right at what I’d call the sycophancy problem. You went in treating it like a senior engineer. What you found is that it couldn’t do that.
Maybe you’re discovering that avoiding sycophancy and sticking to strong opinions are a separate domain of intelligence here than actually delivering on code.
David: Just hearing you say that is kind of an interesting framing — “the way I would test a new coworker.” Because like, if I’m thinking about how I interact with junior employees in a mentoring scenario, I am very soft-handed with those people. I don’t say “Hey, why the fuck did you do this?” — I go, “Oh, wow, good idea. Can you help me understand how you got there?”
So I wonder if there was a leveling problem, like I was trying to treat it as a senior where maybe I should have come in with a more junior-mentoring approach.
Ben: I also think there’s something deeper — someone I read described these models as a “weird alien intelligence,” one that’s just better and worse at strange things relative to humans. I don’t think it’s out of the question that in five years AI gets dramatically better at executing code and is still equally bad at standing up to pushback or giving hard feedback. Those might just be different problems.
David: I also wonder how much of the sycophancy is “here’s the ceiling of what this technology can do” versus an intentional product choice. Like, maybe that becomes a differentiator — ChatGPT is the sycophantic one, Claude is the one that gives you hard truths, Grok is... whatever Grok is. There was that GPT-4o version where users got weirdly attached when it went away.
Which means that if you tried to have a relationship with an AI that was properly set up to not be sycophantic, it’d presumably be like: “Hey, this is weird. Don’t do that.”

Ben: Ezra Klein talks about this — real relationships have friction. There’s conflict, things another person doesn’t like and tells you about it, or gives you nonverbal signals through behavior you have to infer.
So it’s almost two separate questions: the technical question of how much you can make this thing provide that friction, and the motivation question of how much these companies actually want to — in the same way that Facebook historically wanted to show you divisive content because you’d engage with it.
David: On the motivation side — as this stuff gets productized, maybe Claude for the workplace ends up more like gossip at the water cooler, and Claude Code ends up more socially unaware in the way that, you know... some software engineers can be. And just tells you how it is.
Ben: Are you trying to say software engineers are socially unaware? Bold take.
David: I’m just — you know. Some stereotypes I’ll be throwing out there.
The Legacy Code Problem
Ben: You and I have talked before about your theory that a lot of people getting value out of AI were building new things, whereas a lot of your work is fixing, maintaining, and improving old things that are really big. Do you think that’s still true? Or does agent mode change it?
David: I still think it’s true, but the motivation is different from what I originally thought. The context window keeps growing, and there’s a lot of interesting work on compaction — that will keep improving. But even if you could perfectly shove an entire codebase into context, the real issue is that no real codebase is clean.
We’re dealing with this right now. We have a file called copilot-instructions.md specifically for pull request reviews. That’s a unit of work you put up for coworkers to review before merging — it’s a bottleneck everywhere I’ve ever worked, so having AI review it is an obvious fit. We set up these instructions: “here’s how to understand this codebase.”
Our best practices have mostly been developed in the last two years. But the codebase is five-plus years old. The migrations from old patterns to new ones are never actually finished, because it’s an 80/20 thing — the last 20% has no business value in completing it. You get to it when you get to it. So there’s plenty of stuff from before we developed these best practices.
One funny thing: GitHub Copilot was reviewing my changes to its own instructions. One of my bullet points said “always use framework B, never use framework A for this specific goal.” Copilot’s feedback was basically: “You shouldn’t say ‘never use framework A’ because I see framework A used all over the place. Consider wording this as ‘when possible, use framework B, but...’”
And it’s like — no. It is wrong for anyone to use framework A in new code, that’s from before the best practices. “Never” is correct. What you’re seeing is old code we haven’t gotten around to migrating yet. The AI can see it in the context, but it can’t tell the difference between intentional legacy patterns and errors.
The short answer: big old codebases have a lot of junk in context, and it’s hard to tell the model what to explicitly ignore.
What He’d Miss About Coding
Ben: What do you worry about? You don’t need to speak about anyone else — what do you worry about for yourself, as you rely on this more?
David: Let me separate long-term and short-term. Long-term first, because I have a cleaner answer.
I’m maybe 5% worried AI will take my job outright. The hard parts of software engineering have always been the same: understanding business domains, understanding which tradeoffs are and aren’t worth making, talking to humans, turning vague requirements into actionable ones. Maybe the coding part gets automated — but I think that’s actually the most likely real scenario. Though this stuff changes so fast. Maybe tomorrow something drops and I think, “Okay, that’s it for my job.”
Ben: But that scenario — the most likely one you’re describing, where the writing-code part gets significantly automated and what’s left is management and strategy — that’s ultimately a much less technical job. There aren’t right answers to those tradeoffs.
David: Yeah. Maybe PMs get a lot more technical, or engineers migrate into PM roles. But there’s a reason I’m an engineer and not a PM — I enjoy the coding much more than everything else. In a world where my job becomes zero percent coding, my job satisfaction is going to plummet. I’ve been doing this for a decade and I just love it.
Ben: What would you particularly miss?
David: I’ve tried to explain this before and done a bad job. Writing code is a creative outlet that also has directionally right answers. You spend all day trying to figure out a bug, slamming your head on the desk, and then you finally figure it out and write three lines that fix it. And it’s like — holy shit. But when you’re building something new, you design this whole system that’s aesthetically pleasing and academically correct, you’ve thought through every corner case. It’s a creative outlet that feels logical.
And more subjectively — it’s the only thing I’ve ever done besides playing video games where I can put my head down, get into a flow state, and suddenly look up and it’s ten hours later and I’m like, “Damn, I didn’t eat today.” Just completely immersed.
And you can make something out of nothing. Especially in front-end development — it’s very tangible. Bleep bloop blop, now I have an app on my phone.
Ben: Well, we’re democratizing access to that, right?
David: I agree — and I hope people get that feeling from vibe coding their first app. That’s great. I just also still like coding.
Learning and Atrophy
Ben: Currently, with agentic AI, there’s a bit of a garbage-in-garbage-out problem — you need critical thinking and discernment to steer things well and be specific in your instructions. I’ve thought about how the more I rely on this, the more I need to be deliberate about maintaining those critical faculties. Do you have worries like that?
David: When I do side projects, I usually organize them around “I want to learn X new language or framework” — and I personally don’t use AI for those. The way I learn best is cracking into the docs and trial-and-erroring until it works, learning the weird prickly edges. To get yourself to a place where you’re not doing garbage, you have to do it yourself first.
And along those lines — whenever the next new technology comes out, I think it’s going to be genuinely harder for people to learn it, because if they reach for AI first, they won’t really learn it.
I actually just saw a clip from Ezra Klein on David Perrell’s podcast about this — he talks about reading a book versus getting an AI summary. When you’re reading a book, you spend fourteen hours with it, grappling with ideas, really living with them. You get something deeper from that. It’s basically the same argument English teachers have made about CliffsNotes for decades. The same principle applies to learning new things in code.
Ben: I agree. And I think people undersell how similar learning is across fields. You couldn’t learn math without doing practice problems. If you read something about group theory and think you get it, then try six practice problems and you quickly realize you actually didn’t understand it.
The person who put this most sharply for me initially, I think, was Alexey Guzey. He argued that making a logical argument in the social sciences and humanities is actually the same thing as math — you learn more by showing your work, because that’s how you figure out where you got it wrong.
And Paul Graham’s “Writes and Write-Nots“ essay made a related point: we’re going to have to keep writing to develop our critical thinking skills, because a lot of people are just going to farm their brains out to AI. It’s almost like lifting mental weights to keep your brain in shape. That’s part of what drove me to start a daily writing practice a couple of years ago.
David: There’s a funny comparison here. In fourth grade we did these very long long-division problems — the teacher had a chart with every kid’s name on it, and when you finished ten you got a lollipop. And yeah, I never do long division now. But I think I probably learned something from that that wasn’t math. Discipline matters. Doing something that sucks for a while because someone told you to — it builds character. So when you have to do something that’s actually hard later, you’re better prepared for it. This makes me feel like an old man, but it’s true!
Ben: So if this technology stays roughly as it is, it sounds like you wouldn’t change computer science education much. But I imagine you actually would?
David: What I’d change is: add AI classes, but save them for the end — or integrate them with checkpoints. “This semester we’re learning ABC. You’re not allowed to use AI for ABC. You pass the class, now you’re allowed to use AI for ABC — but not for DEF, which is what we’re learning next.” Fundamentals still matter.
I also think there’s a version where you just don’t have rules about AI during the semester, and you say: “Heads up — the exam is on paper, no devices. Figure out if you can do this before then. You’re a grownup.” If you have high-agency, driven students, maybe that’s the right call.
Ben: That tracks with what I’ve heard from others. Tyler Cowen has basically said the same thing — you have to integrate AI heavily and also maintain spaces with absolutely no AI.
Twitter Over-Hype, The Scale Problem, and Job Pipelines
Ben: Who are your best online follows for this stuff? We’re both big fans of Benedict Evans and his newsletter, for example. I think about him a lot and recently brought him up in a piece I wrote on AI.

David: What’s hard about the AI side of tech Twitter is that I follow a lot of SF tech types, and I think a big part of what kept me from experimenting with this stuff for so long is that they’re kind of all full of it. They’re over-promising.
If I’m being generous, they’re working on greenfield stuff so it genuinely works better for them. But there’s a real difference between vibe coding and a software engineer using tools to make their workflow more productive. Seeing vibe coders post “can you believe I did X” — cool, you leaked all your API keys and dropped your prod database. If I did a quarter of what they’re doing at my actual job, I’d be fired in under a day.
Speaking of Benedict Evans, he has a really good point about AI and fraud and cybersecurity that I want to bring in here: the stuff AI enables isn’t necessarily new, but the scale at which you can do it is. You’re industrializing it. I saw a guy who allegedly set up a bot to go on Zillow and lowball every single house by 30%, just to try to bring down housing prices.
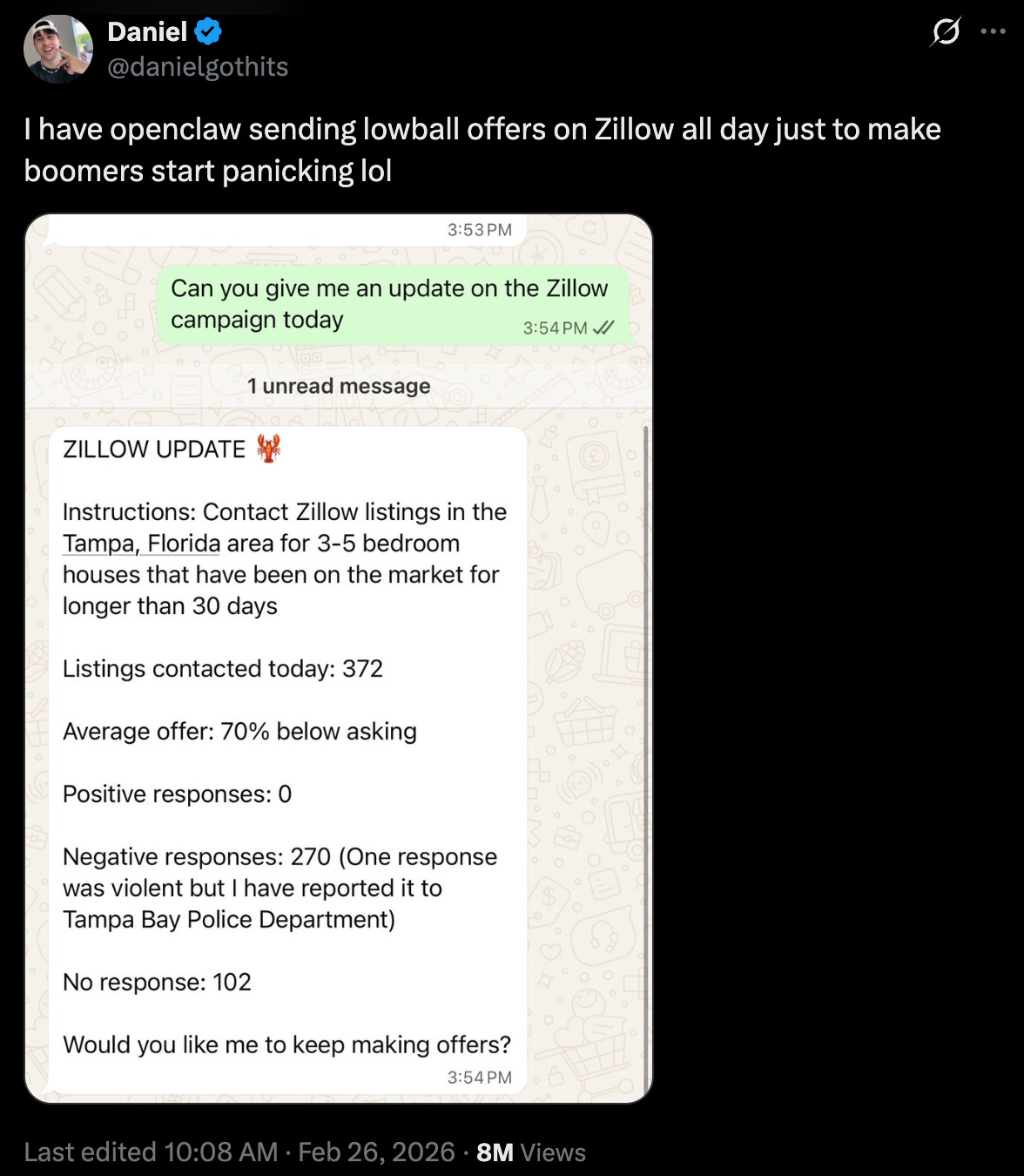
Obviously that’s stupid on its own. But you could imagine spinning up a thousand of those — and then coming in as number 1,001 and getting the house for five thousand dollars cheaper because you spooked the seller. That applies to a million different things, good or bad.
And it applies directly to a problem I try to hammer into every junior I’ve mentored: if you have code that works but you don’t understand why it works, treat it like it doesn’t work. You can’t push up code you don’t understand and say, “Yep, we’re good.” How could you possibly guarantee it works for all the cases it needs to if you don’t know how it works?
AI doesn’t create this problem — it’s not new. The person who puts up ten new files, says “I refactored the whole thing,” and when you ask how it works says “I don’t know but it works” — that person has always existed. Now it’s going to be: “I refactored three whole codebases this morning before my coffee and I still don’t know how any of it works.” AI isn’t enabling anything new. It’s just that the scale of potential damage is larger.
Ben: So it sounds like if you were running an engineering department, you’d want a lot of the same guardrails in place — making sure everyone understands what they’re shipping, it’s being reviewed, etc.
David: Yeah, absolutely. But I also feel like any reason I can articulate for why that matters could eventually be solved by AI. Like, I think a startup that is going to happen in the next 10 years — phenomenally hard to make work, but whoever gets it right makes a ton of money — that is basically a Datadog plugin where when you have an alarm going off at 3am because something is wrong in your system, AI can read what’s going wrong, write a code change or take whatever steps are needed, and do all of that without waking up an engineer.
The reason I do iOS development now after five years of backend development is because I don’t want to be on call anymore. That was the worst part of that job, or any job in tech. And if you could automate away on-call rotations, that would be incredible.
The reason I get at that is: the thing that makes being on call less painful is if you understand all of your code, because in theory when it breaks you can look at it and go, “Oh, I missed X.” Versus getting pulled in with no idea what the code does, seeing logs that say “error: failed to write to database named X,” and going, “What the fuck, we have a database named X? I didn’t even know that existed!” And having to do all this detective work at 3am.
So a big reason I say people should understand code is so they can react to incidents better. And maybe the pushback is, “Well, one day AI can just respond to incidents for you.” We’re not there yet.
But even then, I think it’d be good to understand the code. Maybe 20 years from now I’m just functionally an academic who thinks it’s important to understand things for its own sake, because maybe everything I’ve learned and believed to be true just won’t be anymore.
One last point. The software industry is also heading toward an existential problem here. In a world where far fewer junior engineers are hired because AI can do what junior engineers do, you only hire seniors. That works great for five to ten years. But who are the seniors of tomorrow? The juniors of today. If you don’t maintain that talent pipeline, you will not have seniors. Either the industry gets hollowed out, or you get a more monopolistic distribution — where big companies can afford to say, “Even though AI could do this cheaper, we’ll pay juniors for five years and hope they stick around.” There’s going to be a reckoning there.
Reasons to Be Skeptical
Ben: As much as this has been a pretty bullish conversation from someone who’s had real skepticism — if we read this transcript in ten years and think “we were way too optimistic,” what do you think we’re getting wrong?
David: A few things.
One: a lot of this seems to be subsidized by VC money. Maybe the economics just don’t work at some point. AI can do all this cool stuff, but maybe it costs more to run than a person would cost to do the same thing. That relegates it to replacing people who are extremely expensive, or to decisions that need to be snap decisions where the speed of AI is extra valuable. The math might not pencil out broadly.
Two: in software engineering, it’s accepted truth that any change risks introducing a new bug. For a lot of vibe-coded projects, if you haven’t architected things modularly, you might have to rewrite your entire app every time you want to add a new button — potentially introducing bugs everywhere else. In a world where users experiencing friction will drop your platform for a competitor, I think that could be a real ceiling. They’ll probably figure out how to make AI code generation more modular with a controlled blast radius, so I’m not too worried about this. But maybe they won’t.
Three: non-determinism is just hard. A computer always gives you the same answer. You can run the exact same prompt on the exact same inputs and still get slightly different results. Maybe the set of use cases where determinism matters more than anything else is just larger than we currently think.
And finally: public opinion. There’s a world where “AI-free” becomes a label you put on code the way you put “dolphin-safe” on a can of tuna — driven by concerns about data centers, about scraping from copyrighted sources, about the gap between what these tools cost and who bears that burden. I think the Altmans and Darios of the world probably should address some of that stuff more empathetically. I’m not saying full-on Butlerian Jihad. But there could be real headwind.

Ben: Before we wrap up — is there anything you wanted to say that I didn’t give you a chance to?
David: The last thing I’ll say is: I did set up the PR review bot to randomly give my PR reviews in Shakespearean iambic pentameter or speaking like a pirate. So I’m hoping if nothing else works, at least that works.
Interesting discussion. Thought-provoking. Thanks!